
Table 1: A contiguous selection from the dictionary text file.
The dictionary consists of the pronunciation, spelling, and major class of a word. In the text file, each line (separated by ASCII NL) consists of one such triplet, each field separated by ASCII TAB. The information basically agrees with that in [Webster 1971], except that some pronunciations have been added, regular inflected forms have been added, multi-word entries and abbreviations and initialisms are omitted, spellings containing accent marks (anything besides letters and apostrophe) are omitted, pronunciations containing non-English phonemes (and ``broad a'') are omitted, and entries lacking either spelling or (possibly synthesized) pronunciation are omitted. The source word list unfortunately does not include the proper names from the back of the book, so I inserted the geographic names required by the test suite. Including multiple spellings or pronunciations for the same word, the dictionary has 329,116 entries.
The pronunciations are strings whose elements are one of 39 phonemes, as described in the table below. The phoneme representations were designed to be one-to-one mappings to the phones, and to use only alphabetic symbols; these constraints greatly aided automatic processing in a Unix environment. Within these constraints, I stayed as close as possible to the source text's transcription, which itself stayed as close as possible to the transcription used in the book. /hw/ as in which is here treated as a sequence of two phonemes, as are the retroflex vowels as in butter (/xr/) and bird (/Xr/) and syllabic consonants (/xl, xn/, etc.). Note also the distinction made here between unstressed /x/ and stressed /X/, contra [Webster 1971]; this is done because they are spelt differently, and the stress information is not carried in our dictionary file. Syllable divisions are not carried, either.
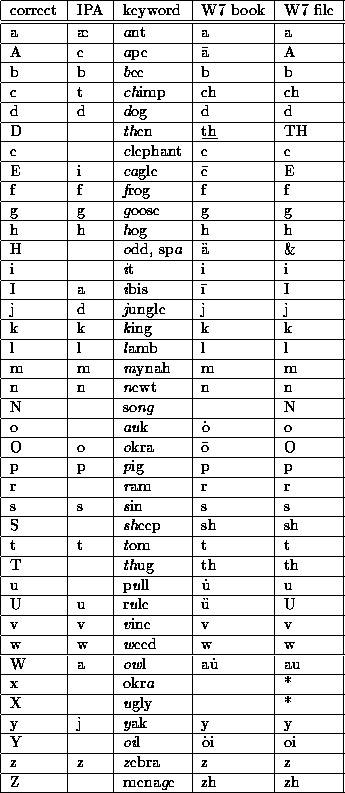
Table 2: Pronunciation
codes used in the dictionary text file, compared with that of
Webster's book and its transcription.
Spellings are ASCII strings as from the dictionary, without syllabification, and with capitalization distinctions preserved. A word may have more than one spelling as it may have more than one pronunciation, but in such cases they simply appear in different entries. Since the text file is sorted by pronunciation, there are blocks of entries that have the same pronunciations but different spellings.
The last field in the text file entry consists of a one- or two-character code for the major class of the word. This is not used by the system except to optionally display to the user the part of speech a particular spelling is associated with, as an aid in distinguishing between candidate respellings. This may be omitted (in which case a ``?'' appears), or there may be more than one code, separated by comma (no space).

Table 3: Word class codes used in the dictionary text file.
It could also be of great assistance to a misspeller to include a short definition or synonym, as an aid in picking out the correct respelling. Such data was not immediately available, however, and has no impact on the rest of this study.