The first step was to get a dictionary in usable machine-readable form. A database system like that of Celex [Celex 1988], which was designed from the beginning for machine use, would be ideal, but it is not immediately available, and does not cover American pronunciations. I have also experimented with using the datafile produced by the Speech Communications Research Laboratory [SCRL 1973], but it is so riddled with errors and absurd pronunciations that I extrapolated that about 300 days of work would be required to make it usable. CSLI also has a copy of Longman's dictionary (LDOCE) on-line. This too was not immediately accessible, and is primarily British, although it does include American pronunciations too. I finally decided on using a locally-available copy of the single-word entries in Webster's 7th collegiate dictionary [Webster 1971], which contains spelling, pronunciation, and major word class. This was an extraction from a keypunched transcription of the book, probably a descendent of the transcription produced under government contract by System Development Corporation in the early 1970's.
The dictionary is less than ideal. Pronunciations are often lacking or truncated, depending on human language expertise to resolve the ``obvious'' pronunciation. (Fully 28% of the pronunciations are fractional.) Often these pronunciations depend on the pronunciation in the previous entry, which is no longer there because multi-word entries were deleted. More seriously, the pronunciations of run-on entries (derived forms not given a definition of their own) were omitted when the extract was made, and the complete transcription did not become available until too late in the project. Also, inflected forms are not given unless they are somehow irregular.
The most important thing to get into shape was the pronunciations. I
estimated that it would require about 80 hours of work to hand-edit
the truncated pronunciations. Instead, I wrote a programme that makes
guesses as to what is intended.![]() Here is the algorithm for suffixed forms
(that is, fractional pronunciations of the form -X): Find the
last syllable in the previous pronunciation whose first segmental
phoneme is the same as the first segmental phoneme of the suffix, and
replace it and subsequent syllables. But if there is no such
syllable, or if that would be the first syllable of the word, replace
the last m syllables of the word, where m is the number of
syllables in the suffix. But if the entry has no more than m
syllables, append the suffix to the end of the word. For prefixes
( X- truncations), the rule was simply to replace the first
m syllables in the previous pronunciation, unless that would be the
whole word or more, in which case the truncation replaces the first
syllable. This rule also worked for another kind of prefix, where the
last element of the prefix is simply the stress mark of the following
syllable; these cases were actually caught by a separate set of
programmes, runon2.nawk and convShPr2.nawk. For infixes
(-X-), the programme substituted the first span of syllables of
which the first syllable had the same initial phoneme and the last
syllable had the same final phoneme as the infix. If there was no
such span, it substituted from the first span of syllables that had
the same beginning; if none, then to the first span that had the same
ending; if none, then it substituted from the second syllable. In all
of these cases, it tried to substitute a span of syllables of the same
length as the truncation, unless that would have involved going into
the first or last syllable. Such relatively ad hoc rules enabled the
programme to expand approximately 90% of the fractional
pronunciations correctly, leaving me with only about a 20 hour task to
edit that programme's output. Instead of modifying the dictionary
directly, the programme worked with an intermediate file (generated by
runon.nawk) that was easier to proof; the edited changes were
incorporated back into the dictionary via expandProns.nawk.
Here is the algorithm for suffixed forms
(that is, fractional pronunciations of the form -X): Find the
last syllable in the previous pronunciation whose first segmental
phoneme is the same as the first segmental phoneme of the suffix, and
replace it and subsequent syllables. But if there is no such
syllable, or if that would be the first syllable of the word, replace
the last m syllables of the word, where m is the number of
syllables in the suffix. But if the entry has no more than m
syllables, append the suffix to the end of the word. For prefixes
( X- truncations), the rule was simply to replace the first
m syllables in the previous pronunciation, unless that would be the
whole word or more, in which case the truncation replaces the first
syllable. This rule also worked for another kind of prefix, where the
last element of the prefix is simply the stress mark of the following
syllable; these cases were actually caught by a separate set of
programmes, runon2.nawk and convShPr2.nawk. For infixes
(-X-), the programme substituted the first span of syllables of
which the first syllable had the same initial phoneme and the last
syllable had the same final phoneme as the infix. If there was no
such span, it substituted from the first span of syllables that had
the same beginning; if none, then to the first span that had the same
ending; if none, then it substituted from the second syllable. In all
of these cases, it tried to substitute a span of syllables of the same
length as the truncation, unless that would have involved going into
the first or last syllable. Such relatively ad hoc rules enabled the
programme to expand approximately 90% of the fractional
pronunciations correctly, leaving me with only about a 20 hour task to
edit that programme's output. Instead of modifying the dictionary
directly, the programme worked with an intermediate file (generated by
runon.nawk) that was easier to proof; the edited changes were
incorporated back into the dictionary via expandProns.nawk.
I next addressed the problem of providing pronunciations for words that do not have any at all. I began by writing Awk programmes to extract the dictionary entries that have neither word class nor pronunciation ( getNoPos.nawk), and those that have word class but lack pronunciation ( getNoPron.nawk). This revealed that there are 35,828 such entries (31% of all entries), of which 9,589 are lacking a word class. A cursory examination showed that when both word class and pronunciation are missing, it is either because the entry is an inflected form whose spelling is not completely straightforward (else the entry would have been omitted entirely), or because it is a given name (e.g., Abby, Ada). If a word class is given but no pronunciation, it is because the word is derived from another word whose pronunciation is given. Sometimes this is through zero-derivation, and so another entry has the required pronunciation; at other times this is through the addition of suffixes.
First I addressed the entries that had a word class but no pronunciation, since the entries lacking word class seem more often dependent on other entries and therefore might be easier to expand if the others were expanded first. The programme matchSpell.nawk used look on a sorted copy of the dictionary to extract entries that have the same spelling as one of those entries, since such words almost always have the same pronunciation. If there were different matches with the same spelling but different pronunciations, these were flagged in the output file, so that I could edit them. This programme turned up 8,825 entries whose pronunciation could be directly inferred from another entry. The programme putProns.nawk put these expanded entries back into the dictionary.
Next I wrote a series of programmes to deal with suffixes that do not shift stress. Grepping the list of pronunciation-lacking words for nouns ending in -er, I extracted 1,883 such words. The programme matchEr.nawk (derived from matchSpell.nawk) searched the dictionary for words matching the stem (e.g., milk for milker), the stem plus -e (e.g., love for lover), the stem with a final geminate consonant trimmed back (e.g., step for stepper), and the stem with final -i replaced with -y (e.g., carry for carrier). The syllable /-xr/ was added to the pronunciations found in the dictionary. Again, multiple pronunciations were flagged, and the list was edited then sifted back into the dictionary via putProns.nawk. This covered 1,796 of the nominal -er words. During this process it was learned that attention should also be placed on the word class of the word sought in the dictionary (much editing of multiple pronunciations could have been saved by accepting only verbs), and on whether the found spelling would derive to the affixed form (for example, there were many instances where the programme wanted to derive words like caner from words like can). Such things were taken into consideration for the follow-up programme match-all.nawk, which could handle several suffixes at once. Derivation is blocked if the suffix starts with a vowel, the dictionary spelling matches the derived word minus the suffix, and that ends in a single vowel followed by a single consonant (other than h, j, q, v, w, x, or y), and all the pronunciations end in a short stressed vowel. I also added the possibility of giving multiple pronunciations for a suffix. The spelling rules were also systematised: i/y alternate except before suffixes beginning with i; gemination and -e dropping occur before suffixes that begin with vowels. For Latinate suffixes that can alternate with other suffixes without changing stress, such as -ism and -ist, a mechanism was set up to exploit such patterns, which are preferred to pure concatenation. Subsequent iterations of match-all.nawk handled cases of where multiple suffixes were added to the same word. After pronunciations were generated for words which had a major class, a similar programme, match-allNoPos.nawk, did the same for words lacking both pronunciation and major class; in this case, word class was inferred from the suffix.
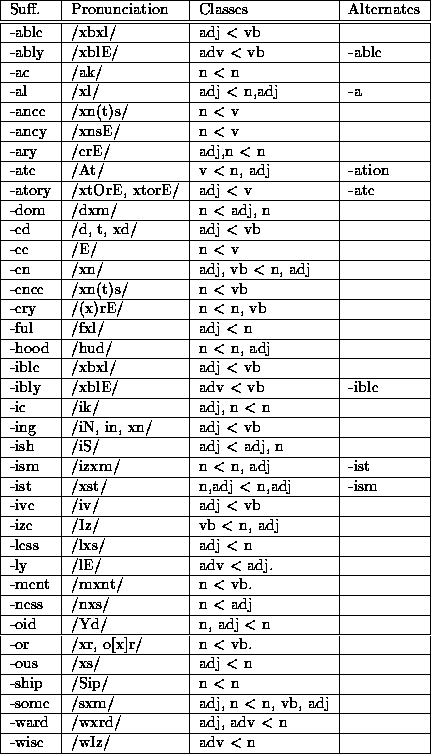
Table 5: Suffixes used in predicting the pronunciation of derived words.
After deriving as many pronunciations as possible, I ran a programme called shortenProns.nawk which converted some of the phoneme codes in the SDC transcription to forms more suitable for manipulation under Unix. In particular, multiletter codes were reduced to single-character codes, and special symbols like & and * were changed to alphabetic codes. For the details about the codes, see section 2.1.1.
I also wrote a programme to add a column stating what inflected forms a word could take (redClass.nawk). These assignments were rather generous, partly because I did not want to rule out rare but permissible forms (such as the plurals of mass nouns), and partly because I thought overgeneration would make it easier to catch mistakes later: it is easier to spot a strange form like ferrouser than to notice that one has never seen redder. The programme simply played off the major class found in Webster's. Words marked ``n'' were assumed to be able to take the full complement of nominal inflexions, viz., plural, possessive singular, possessive plural (coded n). Words marked ``vb'', ``vi'' or ``vt'' (but not ``va'', ``vp'' or ``vm'') were assumed to be able to take the full complement of verbal inflexions, viz., third person present singular, preterite = past participle, and present participle (V). Words marked ``aj'' or ``av'' were marked as taking comparative and superlative endings (j), unless they were longer than two syllables, or ended in -ed, -ing or -ly. (In retrospect, that list of exclusions should have been longer; in particular, most words with Latinate suffixes seem not to take such endings.) All other words were marked 0. Such codes are used by subsequent programmes to generate inflections on the fly, without the need to carry them in this base dictionary. A few additional codes were defined for the use of human editors, when it is observed that illegal forms are generated: s means that the noun can take a possessive singular, but no plural forms; p that a plural base form can take a possessive plural; and v that a verb can take the third person singular present ending and a present participle, but no regular past form.
This concluded the one-shot programmes used to expand the Webster dictionary file. I should stress that no effort was made to systematically check each entry for errors, and many remain, some of which were introduced by these attempts to flesh out omitted pronunciations and inflected forms. Subsequent processing of the dictionary was done in a fully automatic way by the programmes I will describe next. Since they have the property of sometimes deleting information, I wanted to be able to focus all human editing on this particular instantiation of the dictionary, which is called dict, so that corrections could also be used in other projects. For example, when automatic alignment would fail because the dictionary had a mistranscribed pronunciation, then even though alignment was operating on a derived form of dict, I would go back and edit dict, then regenerate the derived dictionary. A Unix Makefile made this process of regeneration fully automatic.
The first step in processing the dictionary is to apply remSup, an executable compiled from an Awk programme. This programme removes words lacking pronunciations, pronunciations with non-English phonemes, and spellings with accent marks. It also inverts the dictionary so that pronunciations come first, emphasizing the intended ultimate use of the dictionary; entries with multiple pronunciations now become multiple entries The pronunciations are also massaged. Pronunciations with parentheses in them, enclosing optional components, are expanded into all the alternatives expressed by that notation. Stress marks are shifted so that they immediately precede the stressed vowel, making it easier to apply them to the one task they are used for (seeing if a vowel is stressed in order to decide if the final consonant should be doubled on adding a suffix). Syllable divisions are removed. Stressed /x/, a symbol which in Webster covers both unstressed schwa and the vowel in sun, is converted to /X/ so that the two may be distinguished after a later programme removes accent marks. Finally, syllabic consonants, marked in Webster by a raised schwa, are remarked to have an ordinary schwa /x/.
Further processing is done by the C programme addInfl. Entries marked with a non-zero inflectability code as discussed above under redClass are expanded into several entries, one for each inflection. Since this programme is the last module that needs word stress information, stress marks are also removed. In adding inflectional affixes, care is taken to observe all the regular spelling rules. The details are in the file AddInfl.c. They cover dropping of final -e before -e; also before -i, unless the stem ends in -ee, -oe or -ye; changing -ie to -y- before -i; inserting -k- after -c before a front vowel; doubling final single consonant after a single short vowel when adding a vocalic suffix; changing -y to -ie- before -s. addInfl also applies a few morphophonological rules, such as restoring /g/ after /N/ when forming comparatives and superlatives, and the choice of allomorphs when adding -s or -ed after different phonemes.
The dictionary is then sorted by pronunciation, and redundant entries are removed, using standard Unix utilities. The result is stored as oneDict, which is the form used as the dictionary text file by the correct programme.