The most important metrics of a spelling corrector are how often it guesses the correct spelling for a word, and how close that correct spelling is to the top of the list of guesses. In developing this prototype, I was not particularly concerned with time and space efficiency, except insofar as great wastage would be pointless and easily correctable. As for a source of errors with which to test, I followed [Damerau 1964] in following [Blair 1956] in using a set of 117 ``spelling demons'' taken from [Hutchinson 1956]. There is no indication that these are gleaned from naturally found errors, and they have been selected for a particular pedagogic purpose, but there is value in using a test suite that has been employed on different spelling correctors. Perhaps a better approach would be to read a large amount of prose and pick out the misspellings, as was done recently in the spelling corrector work of [Pollock 1984]; better still would be controlled experiments where one could distinguish conceptual errors from unintentional typographic errors. Such approaches to evaluation will, however, have to wait for additional sources of funding.
The test suite is included in the appendix.
To run the test suite, the first column (misspellings) was extracted
and fed into the standard input of correct, using a particular
sorting option; a Makefile is responsible for running the test suite
once with each option. A programme called evalRun.nawk then
evaluates each run to see which spellings were correctly guessed
(using the second column of the test suite, which shows the correct
form) and what the rank of the good guess was. Then it calculates
basic statistics across the run: the range of ranks and their average,
and the rank-weighted success rate, where correct guesses ranked
n are adjudged to have 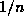 of the correctness of a first-ranked
guess (and failures no weight at all).
of the correctness of a first-ranked
guess (and failures no weight at all).
Of course, all runs had the same unweighted success rate, since they all make the same guesses, just in different order. On this test suite, correct had a correct guess for 114 out of 117 errors (97%). The three words it couldn't guess at all were heartrendering as a spelling of heartrending, rhododrendon for rhododendron, and Wedensday for Wednesday. The first two fail because they clearly reflect creative pronunciations not found in the dictionary; the last seems to be an arbitrary stab at remembering a unique spelling.
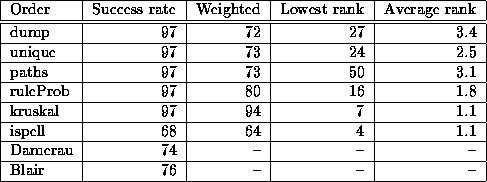
Table 4: Test suite results using various sort
orders for correct, and compared with another corrector and two
research projects. The success rates (percentages) are both absolute and
rank-weighted so that good guesses at rank n are weighted 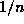 .
The next two columns give the lowest and average rank of the correct
guess.
.
The next two columns give the lowest and average rank of the correct
guess.
In the dump sort order, where respellings are presented in the order guessed, the table shows that the rank-weighted success rate was 72%, with the ranks averaging 3.4. One might think that eliminating duplicates (in unique order) would improve the ranking, but effects were small.
Along the way I wondered whether there might be some advantage to ranking the words according to how many times they were generated as a respelling. After all, if several different ways of looking at a word come up with the same pronunciation, it might seem more likely that one of them is what the misspeller had in mind. This technique, paths, turned out to be worse than unique, with the lowest rank plummeting to 50 (for Britian/Britain).
The preceding evaluations frankly were idle tests done largely because they were easy to do. The first trial of a sorting mechanism that I thought had some chance of success was ruleProb. This technique, it will be recalled, orders the respellings by the average frequency of the sound-spelling correspondences inferred to contribute to the misspelling. The performance gain was not overwhelming, but inspection of the test data shows that most low rankings rose substantially. The rank-weighting formula so punishes ranks below first place (it would take ten tenth-place guesses to equal one first rank guess) that such efforts don't count for much more than failure. The range of ranks is however promising: a standard 24-line terminal would have enough lines to display enough guesses in ispell-style (one guess per line) that the correct word would appear on the first screen. Thus ruleProb would be usable, though not optimal, in a spelling corrector.
A final technique was to use Kruskal's algorithm to compute the
Levenshtein distance between the misspelling and candidate
respellings, then sort by increasing distance (kruskal). In
other words, respellings most similar to the misspelling came out on
top. We also minor sort by the correspondence frequencies, since
Levenshtein distance ties so often. This method performed much better
than the others, with a rank-weighted success rate of 94%, with good
guesses ranking no lower than seventh place.![]()
This compares favourably with ispell, which corrected only 79 misspellings (68%). This is a little lower than the figures from Damerau's study, where using a perfect dictionary on the same test suite enabled his programme to guess 74% of the words correctly. Blair's rather different technique, which involved comparing tetragramme keys on correct and incorrect spellings in the same test suite, achieved a similar success rate.
Such results are promising. The overall success rate of 97% is much higher than the discouraging results reported for phonemic methods in [Alberga 1967]. The rankings of the correct guess are also particularly impressive when one considers that a full dictionary containing 329,116 entries was used, thus giving ample opportunity for ambiguity. On the other hand, the programme (which has not been tuned for performance) is much slower than ispell: it requires 2.6 seconds to present all the respellings of a word on a Hewlett-Packard 9000/370 workstation (a Motorola 68030 machine), compared with 0.1 seconds for ispell. More importantly, the test suite, although chosen because it allowed comparison with earlier work, is decidedly friendly to this application. The test suite, like correct itself, addresses conceptual mistakes, and is clearly not intended to cover mechanical, typographic errors. ispell, which obviously works only on keyboarded text, is no doubt designed to handle all sorts of errors, among which simple keystroke errors probably predominate [Pollock 1984].
It however was precisely my intent to cover only the conceptual errors, and the evidence is that correct does a good job of it. One could well envision an application where Respell and Kruskal are embedded in ispell or a similar programme, which would normally follow traditional techniques to detect misspellings and present respellings based on the single-error model. However, when the user is dissatisfied with all the proferred choices and requests more guesses, the programme could generate additional pronunciation-based guesses and display them in kruskal order. This would be the best of both worlds and cover a significantly higher percentage of misspellings than either system alone.